16 avril 2024
Comprendre et construire des applications basées sur les modèles de langage de grande taille (LLMs)

Les modèles de langage de grande taille (Large Language Models ou LLMs) marquent une avancée majeure dans le domaine de l’intelligence artificielle, en particulier dans la compréhension et la génération de texte imitant le langage humain. Leur capacité à exécuter diverses tâches, telles que la génération de texte, la traduction, la réponse à des questions et la synthèse, en fait des outils puissants pour une large gamme d’applications.
Fonctionnement des LLMs
Les LLMs reposent généralement sur des architectures basées sur les Transformateurs (Transformers), qui utilisent le mécanisme d’attention pour se concentrer sur les parties pertinentes du texte d’entrée lors de la génération de réponses. Le processus d’entraînement des LLMs implique l’alimentation de modèles avec des ensembles massifs de données textuelles et de code, permettant aux modèles d’apprendre des relations complexes entre les mots et les phrases.
Les modèles génératifs d’IA sont devenus de plus en plus sophistiqués et diversifiés, chacun ayant des capacités et des applications uniques. Voici quelques exemples notables :
- Gemini (anciennement Bard) est un chatbot IA de Google utilisant le traitement du langage naturel pour interagir de manière fluide et répondre aux questions. Il peut améliorer les recherches Google et être intégré à diverses plateformes.
- ChatGPT est une variante du modèle GPT (Generative Pre-trained Transformer) développée par OpenAI, spécifiquement ajustée pour des réponses conversationnelles, utile pour le service client et la création de contenu.
- DALL-E, également développé par OpenAI, est un modèle de génération d’images à partir de descriptions textuelles, capable de créer des images complexes et imaginatives basées sur des invites simples.
- MidJourney est un outil d’IA générative qui crée des images à partir de descriptions textuelles, utilisant des modèles de langage et de diffusion pour produire des images réalistes.
- Stable Diffusion est un modèle de deep learning qui utilise des processus de diffusion pour créer des images de haute qualité à partir d’images d’entrée ou de descriptions textuelles.
Composants clés des LLMs
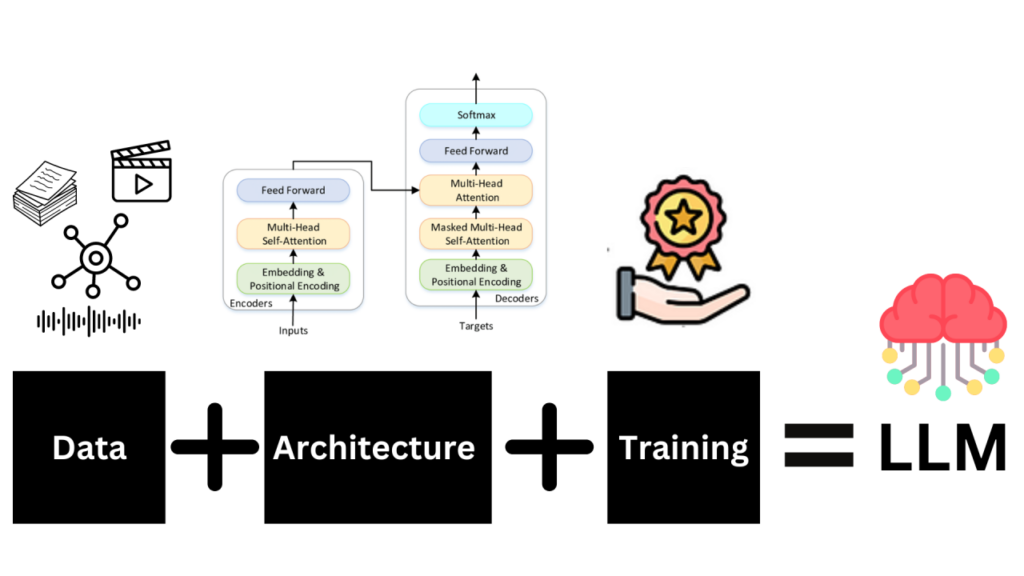
Les LLMs sont construits sur trois piliers fondamentaux : les données, l’architecture et l’entraînement.
- Données : Les données sont la pierre angulaire de tout LLM. La qualité, la diversité et la taille de l’ensemble de données déterminent les capacités et les limitations du modèle. Les données proviennent généralement d’une grande variété de sources textuelles, permettant au modèle d’apprendre des motifs linguistiques variés.
- Architecture : L’architecture sous-jacente du modèle, souvent basée sur les Transformers, est cruciale pour traiter des données séquentielles comme le texte. Les Transformers utilisent des mécanismes d’attention pour évaluer l’importance des différentes parties des données d’entrée, permettant au modèle de comprendre et de générer du texte cohérent.
- Entraînement : Le processus d’entraînement consiste à ajuster les paramètres internes du modèle pour minimiser les erreurs de prédiction, souvent à l’aide de l’apprentissage supervisé. L’entraînement ne se limite pas à l’apprentissage du langage, mais inclut également la compréhension des nuances, du contexte et la capacité à générer des réponses créatives ou inédites.
Processus d’apprentissage des LLMs
Il est essentiel de comprendre comment ces modèles sont entraînés :
- Entrée : Le modèle commence avec un corpus de données textuelles diversifié provenant de sources variées, servant de matériau brut pour l’apprentissage des motifs linguistiques.
- Tokenisation : Le texte est divisé en tokens, qui sont des sous-unités comme des mots ou des sous-mots, facilitant le traitement du texte par le modèle.
- Token Embeddings : Chaque token est transformé en une représentation numérique appelée embedding, qui encode le sens des tokens dans un espace vectoriel.
- Encodage : Les embeddings passent par les couches d’encodage du modèle Transformer, où ils sont traités pour comprendre le contexte de chaque mot au sein d’une phrase.
- Modèle Transformer Pré-entraîné : Le modèle utilise des mécanismes d’attention, des réseaux neuronaux feedforward et de nombreux paramètres pour capturer les complexités du langage.
- Retour Humain : Des boucles de rétroaction humaine peuvent affiner les performances du modèle en ajustant ses sorties selon les attentes humaines.
- Décodage : Le modèle génère du texte en prédisant le mot suivant dans une séquence, en convertissant les embeddings traités en texte lisible.
Construire une application basée sur un LLM
Pour construire une application basée sur un LLM, il est crucial de suivre ces étapes :
- Se Focaliser sur un Problème Unique : Identifier un problème précis et mesurable, suffisamment petit pour permettre une itération rapide, mais assez grand pour impressionner les utilisateurs avec une solution efficace.
- Choisir le Bon LLM : Sélectionner un modèle pré-entraîné approprié en tenant compte de facteurs comme la licence commerciale, la taille du modèle (par exemple, entre 7 et 175 milliards de paramètres), et l’adaptabilité à l’application spécifique.
- Personnaliser le LLM : Adapter un LLM pré-entraîné aux tâches spécifiques en ajustant ses capacités pour générer du texte sur un sujet particulier ou dans un style spécifique.
- Configurer l’Architecture de l’Application : Développer l’architecture de l’application en trois catégories principales : l’entrée utilisateur, l’enrichissement des entrées et la construction des invites, ainsi que des outils d’IA efficaces et responsables.
- Évaluations en Ligne : Réaliser des évaluations en ligne pour mesurer la performance du LLM en interaction directe avec les utilisateurs, permettant des ajustements en temps réel.
Limitations des LLMs
Malgré leur puissance, les LLMs ont des limites notables qui peuvent affecter leur efficacité dans les applications du monde réel :
- Contexte Manquant : Les LLMs peuvent parfois manquer de compréhension du contexte global, entraînant des réponses inexactes ou non pertinentes.
- Sorties Non Personnalisées : Les LLMs peuvent générer des réponses génériques qui ne répondent pas aux besoins spécifiques des utilisateurs.
- Vocabulaire Spécialisé Limité : Les LLMs formés sur des données générales peuvent manquer du vocabulaire spécialisé nécessaire pour certains domaines.
- Hallucinations : Les LLMs peuvent parfois inventer des informations ou produire des sorties biaisées, inexactes ou trompeuses.
Ces limitations peuvent être atténuées grâce à des techniques telles que la Retrieval-Augmented Generation (RAG), l’ingénierie des prompts, et le fine-tuning pour aligner les réponses du modèle avec les exigences spécifiques des utilisateurs et des contextes d’application.
Conclusion
Les LLMs offrent des possibilités immenses pour l’inférence et la génération de texte, mais leur utilisation nécessite une compréhension approfondie de leur fonctionnement, de leurs forces et de leurs limites. En combinant ces modèles avec des techniques avancées comme RAG et le fine-tuning, il est possible de développer des applications puissantes et contextuellement pertinentes qui répondent aux besoins complexes des utilisateurs dans divers domaines.
A la une
-
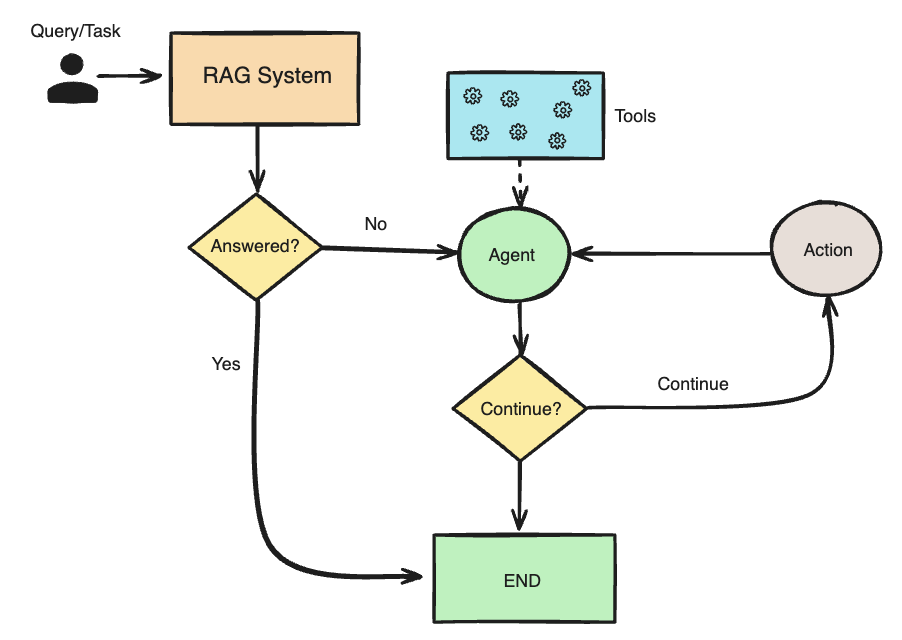
19 juin 2024
Agentic RAG : une révolution dans l’inference d’IA avec LangChain, Ollama, et CrewAI
L’intelligence artificielle (IA) ne cesse de repousser les frontières de ce qui est possible dans ... -
16 avril 2024
Comprendre et construire des applications basées sur les modèles de langage de grande taille (LLMs)
Les modèles de langage de grande taille (Large Language Models ou LLMs) marquent une avancée ... -

23 février 2024
Comprendre les différents types de cloud et leurs distinctions
Dans le domaine de la technologie, la terminologie est souvent utilisée sans consensus clair quant ...